Nach unserem Kurzurlaub habe ich meine Frau gefragt, ob sie den kleinen Reise-Router nützlich fand. Die Antwort war ein klares Ja. Es hat ihr gefallen, dass wir den kleinen Router nur mit einem USB-Anschluss versorgen und mit einem Uplink verbinden mussten und alle unsere internetfähigen Geräte waren ohne weitere Konfiguration wieder online. Das freut mich sehr, denn genau dies war der erhoffte Effekt.
Mir ist aufgefallen, dass ich das LuCI-Webinterface nicht mit den Webbrowsern meines Android-Smartphones aufrufen kann, mit denen meines Android-Tablets aber schon. Ich nutze auf beiden Firefox und Firefox Klar. Falls jemand eine Erklärung, für dieses Mysterium hat, freue ich mich über einen Kommentar.
AdBlock Fast klemmte zu Beginn. Ein apk update gefolgt von einem apk upgrade auf der CLI löste das Problem jedoch schnell in Luft auf.
An Plätzen, an denen kein Uplink-WLAN verfügbar war, habe ich den mobilen Hostspot meines Smartphones als Uplink benutzt. Auch dies hat gut funktioniert. Da sich das Smartphone meist in meiner Hosentasche befindet, habe ich mich einige Male damit aus der Reichtweite des Reise-Routers entfernt. Dramatisch war auch dies nicht, wurde jedoch umgehend durch humanoide Überwachungssysteme angezeigt. ;-)
Natürlich hat GL.iNet mit dem Mudi 7 (GL-E5800) auch für dieses Luxusproblem eine Lösung im Angebot. Allerdings sind mir die ca. 425 Euro für diesen Luxus etwas zu viel. Kennt ihr Alternativen, die über ähnliche Funktionen verfügen? Also klein, kompakt und fähig eine SIM-Karte zu tragen? Dann teilt diese doch bitte in den Kommentaren.
Der Reise-Router hat sich während einer Dienstreise und einer viertägigen Urlaubsreise bewährt und wird uns bzw. mich auch zukünftig auf diesen Reisen begleiten.
Getreu dem Motto „Nutze Gutes und schreibe darüber“ stelle ich im heutigen Beitrag die Open-Source-Projekte lab-toolbox, kcli und kcli-toolbox vor.
Lab-toolbox
Die lab-toolbox ist ein Projekt von meinem TAM-Kollegen Chris Huang. Es handelt sich dabei um ein Python-Skript, welches die Erstellung von virtuellen Maschinen (VM) mit Red Hat Enterprise Linux (RHEL) unter KVM/QUEMU vereinfacht und beschleunigt.
Hinter der Idee zu diesem Projekt steckt dieser Anwendungsfall:
Als Plattform-TAMs müssen wir regelmäßig Dinge unter verschiedenen RHEL-Versionen testen. Häufig muss hierzu eine frische VM auf unserem Laptop herhalten, die nach dem Test auch direkt wieder entsorgt werden kann. Dies kann nun bspw. mit dem folgenden Kommando erledigt werden:
Mit diesem einen Befehl werden folgende Aufgaben ausgeführt:
Es wird das aktuelle RHEL 10 Image auf der lokalen Festplatte genutzt, um eine RHEL 10 VM mit 4 GB RAM und 2 vCPU zu erstellen
Das Skript fragt nach einem Passwort für den Konsolen-Login oder bietet an, sich ausschließlich per SSH einzuloggen
Es generiert automatisch die Konfiguration für cloud-init, um:
den aktuellen Benutzer innerhalb der neuen VM zu erstellen
den SSH-Public-Key des Benutzers hinzuzufügen (automatisch oder per Option)
Ist die VM erstellt, können wir uns direkt mit unserem Benutzer und dessen SSH-Schlüssel einloggen.
Es gibt im Internet viele Wrapper-Skripte, welche die Einrichtung von lokalen VMs vereinfachen sollen. Mir gefällt an diesem besonders, dass es einen meiner häufigsten Anwendungsfälle auf den Punkt bedient. Dazu gibt es ein ausführliches README.md mit einer ausführlichen Dokumentation und einigen Beispielen.
Danke Chris, dass du dieses tolle Projekt mit uns teilst.
Kcli
Wenn es ein bischen mehr sein darf und z.B. folgende Funktionen gewünscht sind:
Deplyoment von Cloud-Images bei verschiedenen Providern (z.B. libvirt, KubeVirt, oVirt, OpenStack, VMware vSphere, AWS, Azure, GCP, IBM cloud and Hcloud) mit einem einzigen Werkzeug
Profile, um VMs mit der gleichen Hardware-Charakteristik zu starten
Komplette Labor-Umgebungen in YAML deklarieren und ausrollen
Große Auswahl an Cloud-Images verschiedener Linux-Distributionen
Einfache Verteilung und Integration von SSH-Schlüsseln
Automatische Registrierung von RHEL-VMs
Dann ist das Projekt kcli von meinem Kollegen Karim Boumedhel und vielen weiteren Beitragenden vielleicht etwas für euch. Wenn ihr jetzt neugierig geworden seid, werft für weitere Informationen einen Blick in die Dokumentation.
Als TAM und Sysadmin möchte ich auch komplexe Systeme testen, welche häufig aus mehreren VMs bestehen. Da mein Laptop hier schnell an seine Grenzen stößt, möchte ich diese Laborumgebungen auch bei anderen Anbietern bereitstellen können. Hierfür scheint mir dieses Projekt gut geeignet zu sein.
Kcli-toolbox
Dies ist der 0,5-Anteil der Vorstellungen in diesem Artikel. Damit ist nicht gemeint, dass es erst zur Hälfte fertig ist. Es ist vielmehr kein richtiges Projekt, sondern lediglich ein Containerfile und ein Custom-Toolbox-Build.
Toolbx ist ein Werkzeug für Linux, welches ein CLI für Softwareentwicklung und Troubleshooting bereitstellt, ohne dass ihr dafür alle notwendigen Werkzeuge auf eurem Host-System installieren müsst. Eine Toolbox basiert auf einem OCI-Container-Image. Es gibt sie in verschiedenen Geschmacksrichtungen. Bitte schaut für weitere Informationen in die Dokumentation.
Bei kcli-toolbox handelt es sich um ein Toolbox-Container-Image, bei dem kcli schon vorinstalliert ist. Das Image wird jeden Dienstag um 03:42 Uhr Ortszeit neu gebaut, um es auf einem aktuellen Stand zu halten.
Mir enthält der Abschnitt „Container Install“ der kcli-Dokumentation zu viele Optionen und aliases, die ich mir nicht merken möchte. Die Builds für EPEL-9 schlagen seit einiger Zeit fehl, so dass ich unter RHEL 9 nicht die letzte Version als RPM nutzen kann. Daher kam mir die Idee zu kcli-toolbox. Ich habe hiermit die aktuellste Version für Fedora 44 und kann diese so natürlich nutzen, als wäre sie als RPM-Paket installiert.
Probiert es doch gerne selbst einmal aus. Hinweise dazu findet ihr in der README.md.
Im Folgenden möchte ich euch einen Proof of Concept (PoC) vorstellen, der aus einem Gespräch mit einem meiner Kunden entstanden ist.
AppStreams != AppStream
Es geht hier nicht um den offenen Standard AppStream, sondern um die in RHEL 8 und RHEL 9 genutzten AppStreams. Letztere sind ein inzwischen abgekündigtes Konzept zur Bereitstellung verschiedener Paketversionen mit einem definierten Unterstützungszeitraum innerhalb eines Major-Release. Für weitere Informationen hierzu siehe den englischsprachigen Artikel: Red Hat Enterprise Linux Application Streams Life Cycle.
Das Risiko
Pakete aus AppStreams werden auf Servern installiert.
Die Unterstützung dieser AppStreams endet und niemand merkt es.
Es wird Software in der Infrastruktur betrieben, die nie wieder ein Update erhält.
User Story
Im IT-Betrieb möchten wir die Lebenszyklusinformationen der AppStreams über eine API abfragen, deren Unterstützungszeitraum abgelaufen ist. Diese Liste möchten wir mit den auf unseren Servern installierten AppStreams abgleichen, um die Installationen zu identifizieren, die aktualisiert oder migriert werden müssen.
Wer seine Systeme an der Hybrid Cloud Console registriert hat, kann mit den abgelaufenen AppStreams gleichzeitig eine Liste der Systeme abrufen, auf denen diese installiert sind. Wer seine Systeme dort nicht registriert hat, kann die abgelaufenen AppStreams abfragen und die Informationen mit eigenen Mitteln weiterverarbeiten, um einen Abgleich durchzuführen.
Zur Demonstration habe ich einen Proof of Concept erstellt:
Die Repos beinhalten eine README.md mit der Dokumentation des Bash- und Python-Skripts sowie Links zu weiterführenden Informationen.
Falls euch dieses Beispiel gefällt, gebt ihm doch gerne einen Stern im jeweiligen Repository oder hinterlasst hier einen Kommentar.
Was gibt es dazu sonst noch wissenswertes?
Die in RHEL Lightspeed enthaltene Roadmap/Lifecycle-Anwendung verhält sich für einige User unerwartet. Als installiert werden AppStreams angezeigt, die auf einem System aktiviert sind. Dies ist auch der Fall, wenn ein Module Stream lediglich aktiviert ist, aber kein RPM-Paket aus diesem Stream tatsächlich installiert wurde. Dies kann zu einer Fehlinterpretation führen.
Red Hat liegt ein Feature Request vor, um dieses Verhalten zu ändern und nur AppStreams aufzuführen, deren RPM-Pakete tatsächlich installiert wurden. Mir liegen keine Informationen vor, ob und wann Red Hat dies umsetzen wird.
Des Weiteren liegt Red Hat die Anfrage vor, die Lightspeed Planning App als on-premises App im Satellite bereitzustellen. Auch hier kann ich leider nicht vorhersagen, ob und wann dies umgesetzt wird.
Falls ihr euch dafür interessiert, nehmt bitte Kontakt zum Red Hatter eures Vertrauens auf.
Ich nutze einen GL.iNet GL-A1300 als Reise-Router. Bei diesem führe ich ein Firmware-Update durch und berichte hier von meiner Erfahrung damit.
Es handelt sich dabei um kein Tutorial oder eine Schritt-für-Schritt-Anleitung, sondern eher um eine persönliche Bewertung. Der Text enthält Links zu den verwendeten Quellen.
Warnung: Ein fehlgeschlagenes Firmware-Update kann euer Gerät unbenutzbar machen. Ich gehe in diesem Text nicht darauf ein, wie man ein Gerät nach einem fehlgeschlagenen Firmware-Update wiederherstellt. Wenn ihr diesem Artikel folgt, tut ihr dies auf eigene Gefahr.
IST-Zustand
Aktuell läuft mein Reise-Router mit der Firmware OpenWrt 24.10.5 r29087-d9c5716d1d / LuCI openwrt-24.10 branch 25.340.26705~d88390b. Zu dem Zeitpunkt, wo ich diesen Text schreibe, ist das Release 25.12.2 aktuell, welches am 27. März 2026 veröffentlicht wurde.
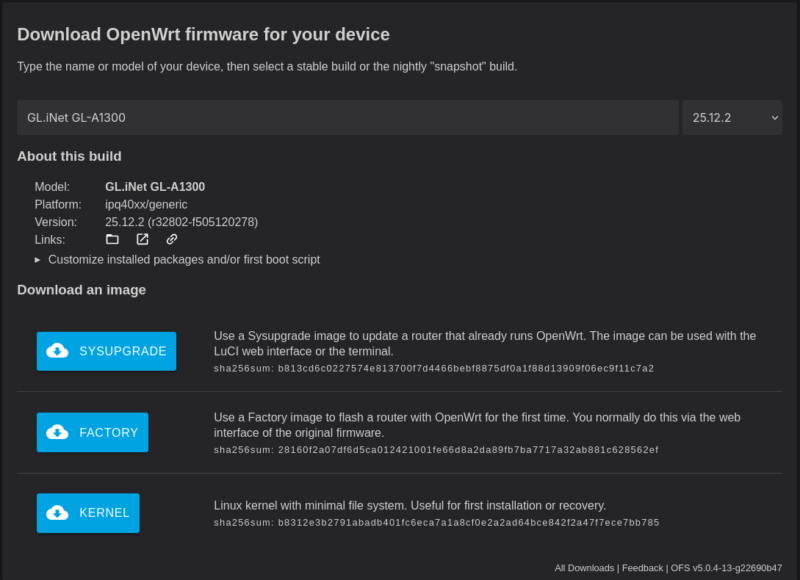
Die Geräteseite im OpenWrt-Wiki weist für mein Modell noch die 24.10.5 als aktuelle Firmware aus. Jedoch haben mich zwei meiner Arbeitskollegen darauf hingewiesen, dass ich besser den Firmware Selector verwenden solle, da dieser aktuelle Informationen beinhaltet, während das Wiki etwas hinterher hängt.
SOLL-Zustand
Die Ergebnisseite des OpenWrt Firmware Selector zeigt für mein Gerät an, dass die Firmware-Version 25.12.2 unterstützt wird.
Firmware-Version 25.12.2 untersützt den GL.iNet GL-A1300.
Dann soll dies die neue Firmware für meinen Reise-Router werden.
Meine Erwartungshaltung
Ich erwarte keinerlei Probleme, sodass ich nach den folgenden 5 Schritten fertig bin.
Ich lade das Sysupgrade für mein Modell herunter.
Ich lade das Sysupgrade im LuCI Web Interface hoch und starte das Firmware-Update.
Der Reise-Router startet neu und lädt die neue Firmware-Version.
Meine Konfiguration wird übernommen.
Ich melde mich mit den bekannten Zugangsdaten an.
Der tatsächliche Verlauf
„Ich mach noch kurz ein Firmware-Update.“
Berühmte letzte Worte eines unbekannten Sysadmins.
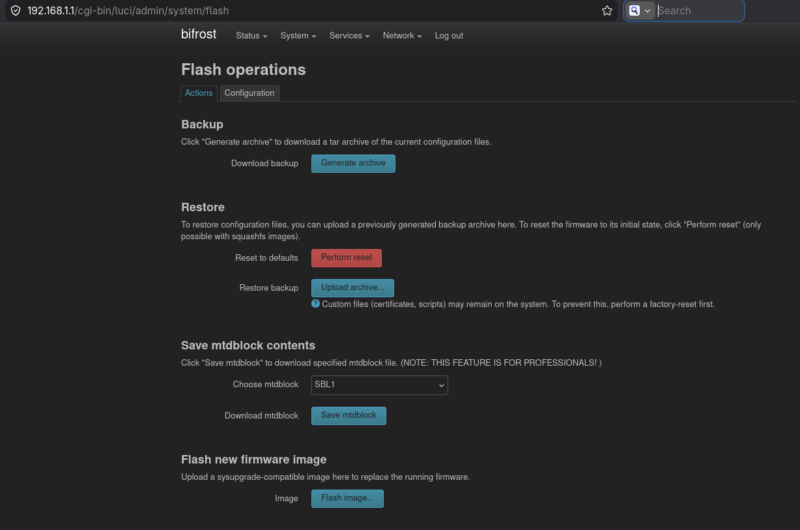
Da es mir die Seite im folgenden Bild anbietet, erstelle ich vor dem Update noch ein Backup. Hierbei wird ein TAR-Archiv erzeugt, welches ich auf meinem Laptop speichere.
Seite im LuCI Web Interface zur Erstellung von Backups und Durchführung von Firmware-Updates.
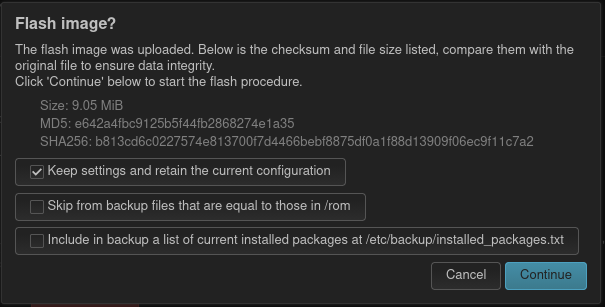
Das folgende Bild zeigt den Dialog, der erscheint, nachdem das Firmware-Image hochgeladen wurde. Ich habe diesen einfach mit einem Klick auf Continue bestätigt.
Bestätigungsdialog zum Start des Firmware-Updates.
Während die Firmware auf das Gerät geflasht wird, blinkt die LED des GL-A1300 schnell. Leuchtet sie wieder dauerhaft, ist das Firmware-Update beendet. Ich verbinde mich erneut mit dem WLAN des Reise-Routers und lade die Seite neu.
Zwar läuft mein Reise-Router jetzt mit der neuen Firmware 25.12.2, jedoch sind die beiden Pakete Travelmate und AdBlock-Fast nicht mehr installiert. Ich vermute, dass dies damit zusammenhängt, dass sich bei dieser Firmware-Verstion der Paketmanager von opkg zu apk geändert hat. Ich verbinde mich daher per SSH zu meinem Router und installiere die Pakete über die Kommandozeile neu:
Nach einem anschließenden Neustart ist auch das Top-Level-Menü „Services“ im LuCI Web Interface wieder vorhanden. Und nicht nur der Menüpunkt auch die Konfiguration der Services ist noch vorhanden. Welch ein Glück.
Vielleicht aktiviere ich beim nächsten Firmware-Update die Option Include in backup a list of current installed packages at /etc/backup/installed_packages.txt. Dies kann mir ggf. die Neuinstallation erleichtern.
Fazit
Die Vorgehensweise beim Firmware-Update ist bei diesem Gerät in meinen Augen nicht ganz so einfach wie bei den gängigen Geräten der Internetdiensteanbieter aber auch kein Hexenwerk.
Ob es mit dem Wechsel des Paketmanagers zusammenhängt, dass ich die Pakete Travelmate und AdBlock-Fast neu installieren musste, kann ich nicht mit Sicherheit sagen. Ich werde das bei zukünftigen Updates mal im Auge behalten.
Nun werde ich erstmal die restlichen Geräte der Familie für die Nutzung des Reise-Routers konfigurieren.
Transparenzhinweis: Der Entwurf dieses Artikels wurde mithilfe der Mistral-KI Le Chat erstellt und von mir redigiert.
Versteckte CLI-Optionen: Warum Entwickler sie nutzen – und warum das umstritten ist
In der Welt der Open-Source-Software gibt es eine Praxis, die immer wieder für Diskussionen sorgt: das Verstecken von CLI-Optionen (Command Line Interface). Diese Optionen sind oft nicht in der offiziellen Dokumentation aufgeführt, werden aber dennoch im Code implementiert – sei es für Debugging-Zwecke, als Notlösung für spezielle Anwendungsfälle oder als „Geheimtipp“ für erfahrene Nutzer.
Ein Beispiel ist der Commit im xfsprogs-Projekt, der die Erstellung von XFS-Dateisystemen kleiner als 300 MB standardmäßig blockiert. Gleichzeitig wurde eine undokumentierte Option (--unsupported) eingeführt, um diese Beschränkung zu umgehen – allerdings ohne Hinweis in der Manpage mkfs.xfs(8) oder Hilfeausgabe.
Doch warum tun Entwickler das? Und welche Vor- und Nachteile hat diese Praxis für Nutzer, Maintainer und die Community?
Warum versteckte CLI-Optionen existieren
1. Flexibilität für Entwickler und Tester
Debugging & Testing: Versteckte Optionen ermöglichen es Entwicklern, spezielle Testumgebungen zu simulieren oder Fehler zu reproduzieren, ohne die Stabilität der Software für Endnutzer zu gefährden.
Beispiel: Im xfsprogs-Commit wird die 300-MB-Beschränkung für automatisierte Tests (fstests) deaktiviert, wenn bestimmte Umgebungsvariablen gesetzt sind. Das verhindert, dass Hunderte von Tests angepasst werden müssen.
2. Schnelle Lösungen für Nischenprobleme
Manchmal gibt es seltene Anwendungsfälle, die so selten sind, dass eine offizielle Unterstützung nicht sinnvoll erscheint.
Beispiel: Die Option --unsupported für mkfs.xfs, da diese im Normalbetrieb gefährliche Folgen, wie den Verlust von Leistung und Redundanz, haben können.
3. Vermeidung von Missbrauch
Manche Optionen sind potenziell gefährlich (z. B. das Umgehen von Sicherheitsprüfungen). Durch das Verstecken sollen nur Nutzer mit entsprechendem Wissen darauf zugreifen.
Die Kehrseite der Medaille: Warum versteckte Optionen problematisch sind
1. Mangelnde Transparenz
Open Source lebt von Transparenz und Gemeinschaft. Versteckte Optionen widersprechen diesem Prinzip: Nutzer wissen nicht, welche Möglichkeiten es gibt, und können die Software nicht voll ausschöpfen und damit nicht uneingeschränkt nutzen.
Frage: Wenn eine Option (nur in seltenen Ausnahmefällen) nützlich ist, warum sollte sie nicht dokumentiert werden?
2. Wartungsaufwand und „Technical Debt“
Undokumentierte Features werden schnell zu „Technical Debt“: Neue Entwickler kennen sie nicht, Nutzer stoßen zufällig darauf und die Optionen werden nie offiziell unterstützt, obwohl sie vielleicht weit verbreitet sind.
Beispiel: Im Linux-Kernel gibt es zahlreiche obskure Kernel-Parameter, die nur in Mailinglisten oder alten Foren erwähnt werden.
3. Frustration für Nutzer
Nutzer, die auf ein Problem stoßen, finden keine Lösung in der Dokumentation, obwohl diese vielleicht existiert. Das führt zu unnötigen Support-Anfragen oder Workarounds.
Beispiel: „Für eigene Tests möchte ich XFS-Dateisysteme kleiner 300 MB erstellen. Bis ich die Option --unsupported im Quelltext gefunden habe, war mir dies nicht möglich, ohne eine veraltete Version von xfsprogs zu nutzen.“
Die Diskussion um versteckte Optionen ist auch eine Frage der Philosophie: Sollte Open-Source-Software maximale Freiheit bieten – auch auf Kosten von Komplexität? Oder sollte sie benutzerfreundlich sein und nur offizielle, getestete Features anbieten?
Was denkst du?
Hast du schon einmal von einer versteckten CLI-Option profitiert oder dich über das Fehlen einer Dokumentation geärgert?
Sollten Projekte wie xfsprogs alle Optionen offenlegen, selbst wenn sie offiziell nicht unterstützt und im IT-Betrieb gefährlich sind?
Oder ist es in Ordnung, wenn Entwickler „Hintertüren“ für spezielle Fälle einbauen?
In diesem Artikel erfahrt ihr, warum ich einen Reise-Router haben möchte, welchen ich aktuell mit welcher Firmware und zusätzlichen Paketen nutze und wie zufrieden ich damit bin.
Ich erhalte weder vom Hardwarehersteller noch von den verwendeten Projekten Zuwendungen irgendwelcher Art für diesen Bericht. Er gibt ausschließlich meine persönliche Meinung wieder.
Motivation
Wir sind eine kleine Familie mit einer ganzen Menge an WLAN-Geräten. Diese Geräte begleiten uns zu Hause wie unterwegs.
Daheim kümmerten sich in der Vergangenheit Pi-hole und heute OPNsense darum, dass wir von Werbung auf unseren Geräten so gut es geht verschont bleiben.
Erst, wenn wir unterwegs sind und z.B. Hotel-WLAN oder öffentliche Hotspots nutzen, fällt uns auf, wie kaputt das Internet eigentlich ist. Unser Kind findet vor lauter Werbung die Spiele auf dem Tablet nicht wieder und der übermäßige Werbemüll vermiest uns jeden Medienkonsum.
Ich habe keine Lust, jedes Gerät einzeln zu konfigurieren, um der Werbeindustrie Widerstand zu leisten. Daher möchte ich einen Reise-Router zu Hilfe nehmen. Die Idee ist, dass ich einen kleinen Router mit dem Hotel-WLAN verbinde, welcher dann für unsere Geräte ein WLAN aufspannt. Dieser Router stellt Dienste wie DHCP, DNS und einen Werbeblocker bereit, welche von allen verbundenen Geräten genutzt werden können.
Zusätzlich lässt sich mit dem Reise-Router auch die Einschränkung in manchen Hotels umgehen, wo sich nur ein einziges Gerät mit den bereitgestellten Zugangsdaten gleichzeitig mit dem Hotel-WLAN verbinden darf.
Dies kommt mir auch beruflich zugute, wo ich meist mit Handy und Laptop reise. So kann ich meine Geräte durch die im Reise-Router integrierte Firewall zusätzlich schützen. Ich kann sogar eine kleine, mobile Laborumgebung mithilfe des Routers aufbauen.
Slate Plus (GL-A1300)
Ich habe auf Mastodon um Empfehlungen gebeten und mit Kollegen gesprochen. Danke euch allen für eure Unterstützung. Am Ende habe ich mich für den Slate Plus (GL-A1300) von GL.iNet entschieden:
Erworben habe ich diesen bei einem großen Online-Gemischtwarenhändler für 76,99 Euro. Anschließend habe ich OpenWrt 24.10.5 via SSH darauf installiert. Das OpenWrt-Projekt ist ein Linux-Betriebssystem für eingebettete Systeme, wie den hier genannten GL-A1300.
Um OpenWrt auf einem Router zu installieren, sind fortgeschrittene Kenntnisse im Bereich der Systemadministration erforderlich. Es besteht trotz guter Software und Dokumentation die Gefahr, dass man sein Gerät bei diesem Vorgang unbrauchbar macht (bricked). Ich beschreibe die Installation hier nicht im Einzelnen und verweise auf das OpenWrt Wiki.
Travelmate, ein Verbindungsmanager für Reise-Router
Travelmate läuft auf OpenWrt und stellt eine Verbindung (Uplink) zum WLAN-Zugangspunkt/Hotspot z.B. des Hotels, der Ferienunterkunft her. Travelmate wird dann zum Zugangspunkt (Access Point) für unsere Geräte und bietet uns einen sicheren Zugang zum Internet.
Travelmate verwaltet alle Netzwerkeinstellungen, Firewall-Einstellungen, Verbindungen zum WLAN usw. und stellt automatisch eine (erneute) Verbindung zu konfigurierten APs/Hotspots her, sobald diese verfügbar sind.
Hilfe zur Installation und Konfiguration bietet die Travelmate-Seite im OpenWrt Wiki. Nach der Installation habe ich Travelmate genutzt, um meinen Reise-Router mit meinem WLAN zu Hause zu verbinden. Dies geht genauso einfach, wie einen Laptop in das WLAN zu integrieren.
Während ich die Zeilen für diesen Abschnitt schreibe, bin ich mit meinem Laptop mit dem WLAN des GL-A1300 verbunden, welcher über mein Heim-WLAN mit dem Internet verbunden ist. Das folgende Bild dient der Veranschaulichung des Testaufbaus:
Testaufbau mit dem Reise-Router GL-A1300
AdBlock-Fast
AdBlock-Fast ist ein leistungsstarker Werbeblocker-Dienst für OpenWrt, der sich in Dnsmasq, SmartDNS und Unbound integrieren lässt. Er unterstützt das parallele Herunterladen und Verarbeiten von Remote-Block- und Allow-Listen und optimiert diese in effiziente, mit Resolvern kompatible Formate.
Die Installation verlief wie beschrieben. Ich habe wahllos einige Block-Listen heruntergeladen und aktiviert. Einen Test werde ich auf meiner nächsten Dienstreise durchführen.
Erster Einsatz im Hotel
Der erste Praxistest erfolgte auf Dienstreise im Hotel.
Im Hotelzimmer wird der Reise-Router über ein USB-C-Kabel und ein Standards-USB-Ladegerät mit Strom versorgt. Ich starte meinen Laptop und verbinde mich mit dem WLAN des Reise-Routers. Anschließend öffne ich das Webinterface des Reise-Routers in meinem Webbrowser. Die Standards-IP-Adresse von OpenWrt lautet 192.168.1.1. Unter Services/Travelmate/Wireless Stations scanne ich nach verfügbaren Netzwerken und stelle eine Verbindung zum offenen Hotel-WLAN her.
Das Hotel bietet ein offenes WLAN ohne Authentifizierung an. Um in das Internet zu gelangen, muss man jedoch zuerst die Nutzungsbedingungen auf einer Portalseite bestätigen. Dies erledige ich über mein Telefon, welches ich mit dem WLAN des Reise-Routers verbinde. Die Bestätigungsseite wird hier einmalig angezeigt. Alle weiteren Geräte können das Internet nutzen, ohne dies nochmals separat bestätigen zu müssen. Denn aus Sicht des Hotel-WLANs ist nur ein WLAN-Client verbunden.
Um den AdBlocker zu testen, habe ich eine Runde in meiner Skat-App gespielt. Ohne AdBlocker sieht man hier sein Blatt vor lauter Werbung nicht. Auch hier funktioniert alles wie gewünscht.
Fazit
Einzig die Firmware auf die Hardware zu flashen erfordert fortgeschrittene Kenntnisse. Die anschließende Nutzung des Reise-Routers ist unkompliziert.
Die Stromversorgung über USB macht das Gerät einfach und flexibel einsetzbar. Die Verbindungsqualität ist gut und der Werbeblocker arbeitet wie erwartet. Evtl. werde ich noch das Wireguard-VPN testen. Dies könnte nützlich sein, um mich zu meinem Heimlabor zu verbinden.
Als nächstes werde ich alle unsere WLAN-Gräte für die Nutzung des Reise-Routers konfigurieren, so dass wir das nicht unterwegs tun müssen.
Am kommenden Wochenende ist es wieder so weit. Mit den Chemnitzer Linux-Tagen 2026 findet die größte Open Source Community Konferenz im deutschsprachigen Raum statt. Und ich freue mich auf ein Wiedersehen mit guten Bekannten und darauf neue Gesichter aus der FOSS-Gemeinschaft kennenzulernen.
Aus dem vollgepackten Programm habe ich mir folgenden Fahrplan zusammengestellt:
Neben dem offiziellen Programm freue ich mich natürlich auf jede Menge interessanter Gespräche mit Gleichgesinnten. Bleibt gesund und bis zum Wochenende in Chemnitz.
In der Vergangenheit habe ich viele Dokumente, wie z.B. Hausarbeiten, Aufsätze, Briefe, Dokumentationen und Präsentationen mit LaTeX erstellt. In der Vorbereitungsphase für einen Vortrag haben Dirk und ich beschlossen, Typst zu lernen.
Ich habe kein Werkzeug zur automatischen Konvertierung genutzt, da ich zu faul war, ein solches erst zu finden und zu erlernen. Stattdessen habe ich Vim genutzt und die entsprechenden Umgebungen ersetzt. Das war in diesem Fall in Ordnung, kann aber bei komplexeren Dokumenten schnell in Arbeit ausarten. Allerdings werden Automaten bei zunehmend komplexen Projekten ebenfalls an ihre Grenzen kommen.
Im Folgenden findet ihr einen kurzen Vergleich der Syntax-Elemente.
Die Preamble (Vorspann)
Die Preamble ist der Teil des LaTeX-Dokuments, der vor dem eigentlichen Inhalt steht. Hier werden grundlegende Einstellungen und Pakete definiert, die während der Dokumenterstellung verwendet werden. Die Preamble beginnt immer mit dem Befehl \documentclass und endet mit dem Befehl \begin{document}.
Die Referenz ist ständig in einem Browser-Tab geöffnet, wenn ich mit typst arbeite. Dies wird so bleiben, bis ich die am häufigsten verwendeten Funktionen auswendig kenne.
Grundsätzlich halte ich mich an das KISS-Prinzip und den Grundsatz: Form follows function (Deutsch: die Form folgt der Funktion bzw. dem Inhalt). Ich möchte mich so viel wie möglich mit dem Inhalt beschäftigen und möglichst wenig Zeit mit dem Satz bzw. der Formatierung zubringen.
Abbildungen und Tabellen
Zu den häufigsten Umgebungen zählen vermutlich Abbildungen und Tabellen. In der LaTeX-Version habe ich diese wie folgt gesetzt:
\begin{tabular}{ll}
Vertragsnummer & 12345\\
Kundennummer & 98765432\\
Tarif & zuhause100\\
\end{tabular}
\begin{figure}
\centering
\includegraphics[scale=0.3]{bilder/bild.jpg}
\caption{Meine super Bildunterschrift}
\label{fig:bild}
\end{figure}
\begin{figure}
\begin{subfigure}[c]{0.5\textwidth}
\includegraphics[width=0.9\textwidth]{bilder/front.jpg}
\subcaption{Frontansicht}
\end{subfigure}
\begin{subfigure}[c]{0.5\textwidth}
\includegraphics[width=0.9\textwidth]{bilder/rear.jpg}
\subcaption{Rückansicht}
\end{subfigure}
\caption{Das sind zwei tolle Abbildungen.}
\label{fig:bild2}
\end{figure}
Für das LaTeX-Konstrukt subfigure habe ich keinen entsprechenden Ersatz in typst gefunden. Ich setze dies in einzelnen Abbildungen hintereinander um. Die Umgebungen sehen nun wie folgt aus:
Tabellen und Bilder werden beide in einer figure-Umgebung gesetzt. Dies macht in meinen Augen Sinn, da beide Umgebungen in der Regel mit einer Über- bzw. Unterschrift versehen werden, häufig zentriert gesetzt und mit einer Referenz versehen werden.
Ich habe mich noch nicht ganz an die Terminologie gewöhnt. Typst bezeichnet figure und table sowie die meisten anderen Elemente als Funktionen und nicht als Umgebungen.
Aufzählungen, Links und Listen
Für nummerierte und unsortierte Listen in LaTeX siehe Abschnitt 3.18. Listen im KOMA-Script Scrguide. Für typst siehe enum und list.
Für Links steht in LaTeX das mächtige Paket hyperref bereit. In typst gibt es das link-Element.
Fazit
Mir erscheint die typst-Syntax etwas einfacher, dafür weniger flexibel zu sein. Was mir besser gefällt, mag ich noch nicht sagen, da ich noch unentschlossen bin.
Das mit LaTeX erstellte PDF sieht in meinen Augen perfekt aus. Das mit typst erstellte PDF sieht ebenfalls gut aus und ist leserlich. Es reicht in meinen Augen jedoch nicht an die LaTeX-Ausgabe heran.
In typst ist meine Preambel kürzer, die Syntax etwas einfacher. Dafür war es mir nicht so einfach möglich, die Schriftart zu ändern. Diese hätte ich erst in meine typst-Binärdatei mit einkompilieren müssen. Ein Vorgang, der mir entschieden zu aufwendig ist.
Probiert es am besten aus und entscheidet selbst, welches Ergebnis euch besser gefällt. Ich vermag (noch) nicht zu sagen, ob mir LaTeX oder typst insgesamt besser gefallen. Werft ggf. zuerst einen Blick in den Guide for LaTeX Users.
Das sind ja gleich mehrere Fragen auf einmal. Doch ich denke, dass man diese gut in einem Beitrag beantworten kann.
Für die Antwort auf die Frage was Execution Environments sind, verweise ich auf die offizielle Dokumentation, da dies sonst den Umfang dieses Beitrags sprengen würde. Kurz gesagt handelt es sich dabei um Container-Images, welche unterschiedliche Versionen von ansible-core und diverse Ansible Collections enthalten.
Ich verwende für die folgenden Beispiele die Execution Environments aka Container-Images ee-minimal-rhel9 und ee-supported-rhel9 von registry.redhat.io/ansible-automation-platform-26.
Option 1: Mit Podman schnell und simpel zum Ziel
Folgender Code-Block zeigt den gesuchten Inhalt für das Minimal-Image an:
[jkastning@aap-1 ~]$ podman run --rm registry.redhat.io/ansible-automation-platform-26/ee-minimal-rhel9:latest ansible --version
ansible [core 2.16.14]
config file = None
configured module search path = ['/home/runner/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/local/lib/python3.11/site-packages/ansible
ansible collection location = /home/runner/.ansible/collections:/usr/share/ansible/collections
executable location = /usr/local/bin/ansible
python version = 3.11.13 (main, Aug 21 2025, 00:00:00) [GCC 11.5.0 20240719 (Red Hat 11.5.0-11)] (/usr/bin/python3.11)
jinja version = 3.1.6
libyaml = True
[jkastning@aap-1 ~]$ podman run --rm registry.redhat.io/ansible-automation-platform-26/ee-minimal-rhel9:latest ansible-galaxy collection list
usage: ansible-galaxy [-h] [--version] [-v] TYPE ...
Perform various Role and Collection related operations.
positional arguments:
TYPE
collection Manage an Ansible Galaxy collection.
role Manage an Ansible Galaxy role.
options:
--version show program's version number, config file location,
configured module search path, module location, executable
location and exit
-h, --help show this help message and exit
-v, --verbose Causes Ansible to print more debug messages. Adding multiple
-v will increase the verbosity, the builtin plugins currently
evaluate up to -vvvvvv. A reasonable level to start is -vvv,
connection debugging might require -vvvv. This argument may
be specified multiple times.
ERROR! - None of the provided paths were usable. Please specify a valid path with --collections-path
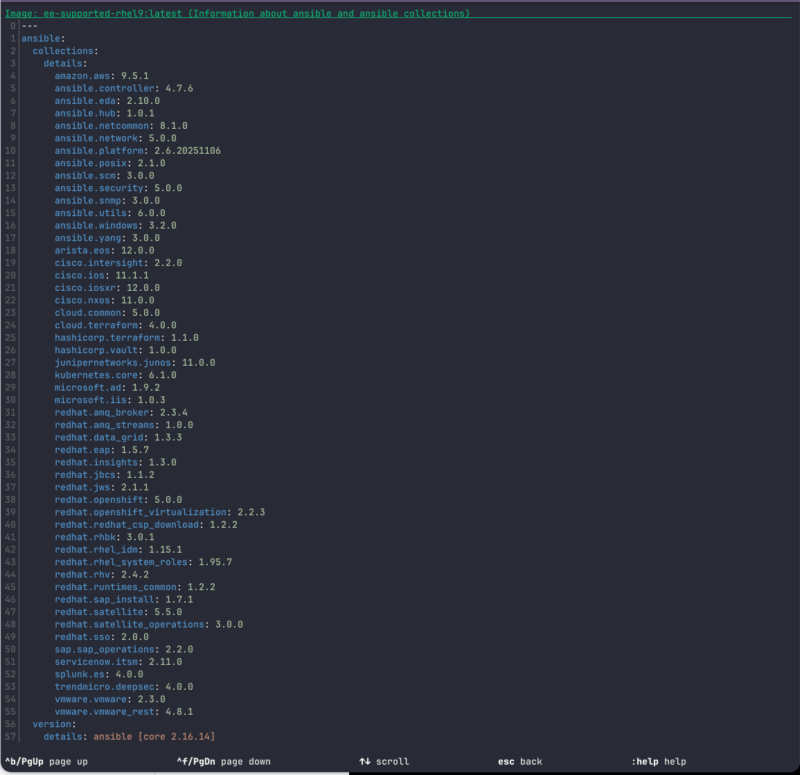
Dieses Image enthält ansible-core in Version 2.16.14 und keinerlei Ansible Collection. Das ee-suported-rhel9 bringt im Vergleich dazu eine ganze Reihe an Collections mit:
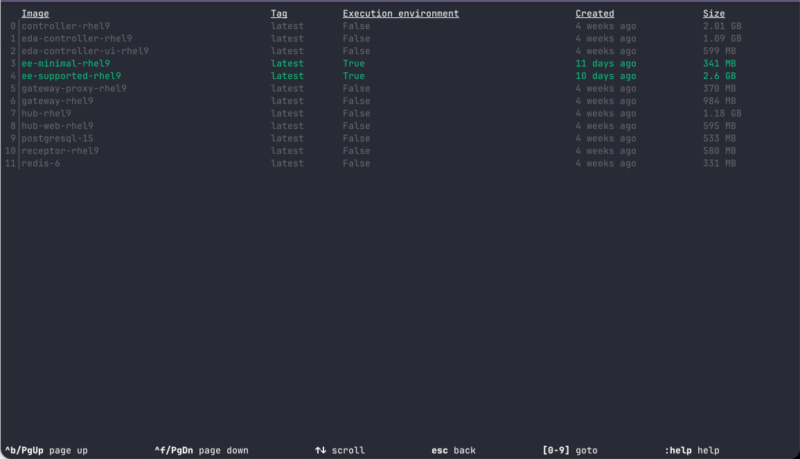
Alternativ kann man das Container-Image aka Execution Environment Image (eei) auch mit dem ansible-navigator untersuchen. Der Befehl ansible-navigator images --eei ee-supported-rhel9 lädt das gewünschte Image bei Bedarf herunter und öffnet einen interaktives Text-Interface, welches alle lokal vorhandenen Images auflistet. Das folgend Bild zeigt eine Ansicht von meinem Labor-PC:
Auflistung der vorhandenen Container-Images im ansible-navigator
Durch drücken der Taste ‚4‘ wird das Image ee-supported-rhel9 ausgewählt:
Auswahlmenü für das Image: ee-supported-rhel9:latest
Wählt man hier die ‚2‘ muss man sich in Geduld üben. Denn die Analyse des Images kann in der Tat etwas dauern. In diesem Fall waren es ganze 2 Minuten!
Auf Computer zu warten kann ich wirklich nicht gut leiden.
Hat man die Wartezeit überlebt, wird man mit folgender Ansicht belohnt:
Ansicht der enthaltenen Ansible Collections und der Version von ansible-core
Fazit
Dieser Beitrag hat zwei Optionen gezeigt, wie man sich die Version von ansible-core und die in einem Execution Environment Image enthaltenen Ansible Collections anzeigen lassen kann.
Ich persönlich bevorzuge Option 1, da diese deutlich schneller zu einem Ergebnis führt, während man sich bei Option 2 für mehrere Minuten gedulden muss. Diese Geduld benötigt man übrigens auch für das Image ee-minimal-rhel9, welches gar keine Collections enthält. Hier betrug die Wartezeit immerhin mehrere Sekunden.
Ich freue mich, Teil eines dezentral organisierten, förderierten, sozialen Netzwerks zu sein und nicht ein Produkt für gewinnorientierte Unternehmen. Es gefällt mir, dass die Dienste und Plattformen im Fediverse frei von Werbung sind und die Inhalte durch die Teilnehmer:innen gestaltet werden. Hier wird meine Zeitleiste nicht von Algorithmen bestimmt, die der jeweilige Anbieter kontrolliert und damit vorgibt, was ich zu sehen bekomme und was nicht. Hier kann ich mir meine Filterblase selbst zusammenstellen.
Das Fediverse mag kleiner sein, als die komerziellen Plattformen. Durch seine dezentrale Struktur mag es nicht allen Menschen gleichermaßen zugänglich sein, die es gewohnt sind zentrale Dienste weniger Anbieter zu nutzen und welche die Föderation verwirrend finden. Dies macht mir jedoch nichts. Ich fühle mich hier wohl.
Und Du? Kennst du das Fediverse? Nutzt Du es selbst? Welche Dienste gefallen Dir gut und welche weniger? Lass es mich doch gerne in den Kommentaren wissen.