In diesem Artikel thematisiere ich, wie sich die Anzahl der entdeckten Schwachstellen in den letzten Jahren entwickelt hat und ob wir noch von Zero-Day sprechen, oder eher von Zero-Hour oder Zero-Minute.
Ich werde darstellen, warum es in meinen Augen bis auf wenige Ausnahmen nicht mehr angemessen ist, nur noch einmal im Jahr oder quartalsweise zu patchen und unter Schmerzen eingeübte Prozesse heute nicht mehr zeitgemäß erscheinen.
Anschließend werde ich euch bitten, eure Erfahrungen anonym mit mir zu teilen. Ich erhoffe mir, so einen besseren Überblick über die Situation da draußen in den Rechenzentren, Serverräumen und IT-Betriebseinheiten zu gewinnen. Mehr dazu unten im Text.
Entwicklung der Bedrohungslage
Die Anzahl der pro Jahr gemeldeten Schwachstellen (CVE) steigt rasant, wie folgendes Diagramm in Abbildung 1 verdeutlicht.
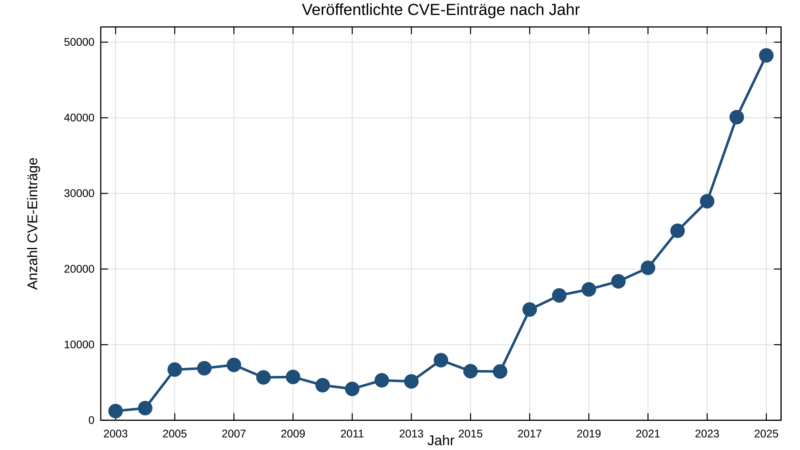
Während sich die Anzahl der CVE pro Jahr erstmalig im Zeitraum von 2016 bis 2017 von ca. 6.500 auf ca. 14.500 mehr als verdoppelt hat, kam es zuletzt in den Jahren 2021 bis 2024 zu einer Verdopplung. Diesmal hat sich die Anzahl jedoch von ca. 20.000 auf knapp über 40.000 gesteigert. Und diese Zahl steigt weiter. So wurden für das erste Quartal 2026 bereits 15.176 CVE gezählt.
Wenn sich dieser Trend fortsetzt, werden wir das Jahr 2026 mit deutlich mehr als 60.000 registrierten CVE abschließen. Das wären 5.000 CVE/Monat oder 164 CVE/Tag.
Gleichzeitig sinkt die mittlere Zeit von der Veröffentlichung eines CVE bis zu einem Exploit, wie Abbildung 2 zeigt.
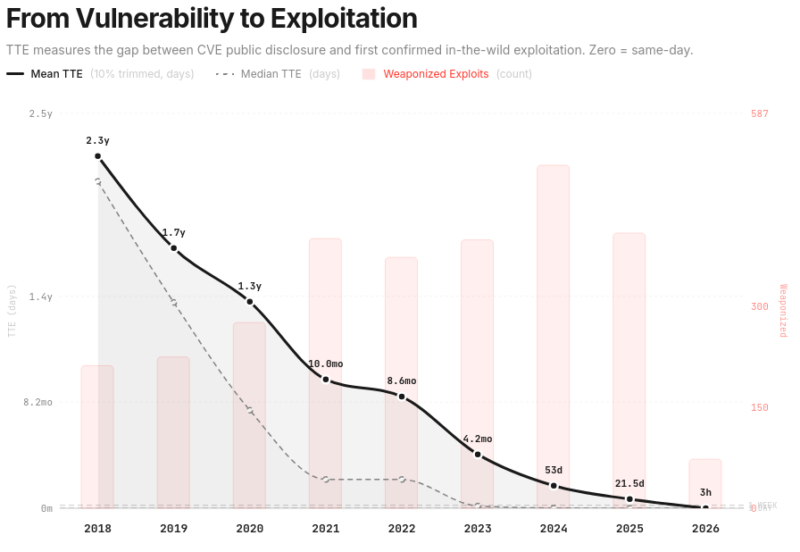
Lag die mittlere Zeit zwischen der Veröffentlichung eines CVE und des Exploits 2023 noch bei über 4 Monaten, ist diese auf 21,5 Tage im Jahr 2025 gesunken. Für 2026 wird diese sogar mit nur noch 3 Stunden angegeben.
Noch bedrohlicher wirkt die Lage, wenn man sich ansieht, für wie viele CVE noch am gleichen Tag oder sogar vor deren Veröffentlichung ein Exploit bekannt wird (siehe Abbildung 3). Man spricht hier auch von Zero-Day-Exploits.
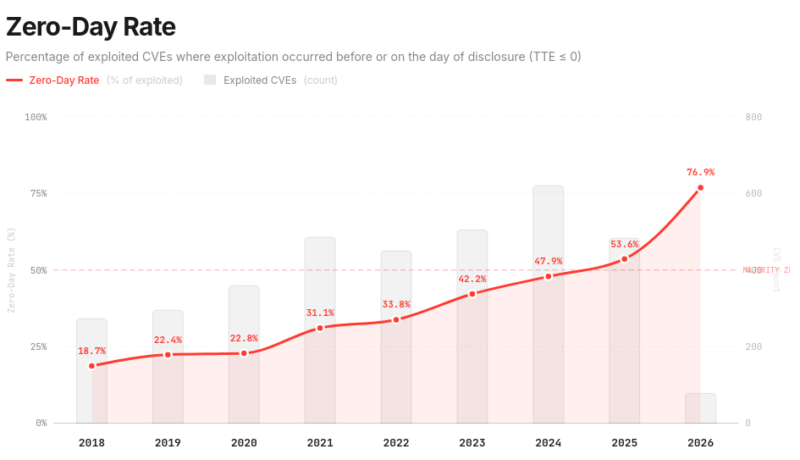
Im Jahr 2024 gab es für 47,9% der CVE einen Zero-Day-Exploit. Im Jahr 2025 war das bereits für mehr als die Hälfte der Fall, nämlich 53,6 %. Das Jahr 2026 ist noch in vollem Gange. Die Rate der Zero-Day-Exploits liegt mit bisher 76,9% nochmals deutlich höher.
Es wird für die Paketbetreuenden, Upstream-Entwickelnden und Software-Herstellenden Menschen immer herausfordernder, einen Patch bereitzustellen, bevor ein Exploit existiert und aktiv gegen verwundbare Systeme eingesetzt wird.
Klassische Ansätze funktionieren nicht mehr
Aus meiner beruflichen Tätigkeit als Red Hat TAM und als Sysadministator bei verschiedenen Unternehmen ist mir bekannt, dass unterschiedliche Unternehmen und Organisationen sehr verschieden mit Schwachstellen und deren Behandlung umgehen.
Allen ist gemein, dass sie für ihre Anwendungen Wartungsfenster vereinbaren, in denen z.B. Sicherheitsaktualisierungen installiert werden, um vorhandene Schwachstellen zu schließen. Einige haben einen Patchday pro Jahr, manche patchen einmal im Quartal und wieder andere monatlich. Einzelne Unternehmen können dies sogar noch schneller.
Die einen haben regelmäßig wiederkehrende Wartungsfenster, die anderen müssen diese bei Bedarf anmelden. Einige haben schlanke Prozesse, einige nutzen Change-Management nach ITIL.
Um die Integrität, Verfügbarkeit und Vertraulichkeit der eigenen Informationssysteme und deren umgebener Infrastruktur zu schützen, sind zwei Grundsätze seit vielen Jahren allgemein bekannt:
- Installiere verfügbare Sicherheitsaktualisierungen so schnell wie möglich.
- Nutze und implementiere Verteidigung in der Tiefe.
Die beiden Grundsätze stehen nicht in einer Entweder-Oder-Beziehung. Sie sollten beide berücksichtigt werden.
In meinen Augen ist es längst nicht mehr zeitgemäß, Sicherheitsaktualisierungen jährlich oder quartalsweise zu installieren. Eine kleine Ausnahme mögen hier Systeme bilden, deren Nutzerkreis stark eingeschränkt ist und auf die ausschließlich über wenige sehr gut gesicherte Kanäle zugegriffen werden kann.
Um es deutlich zu sagen: „Für wochen- oder tagelange Change-Management-Prozesse bleibt keine Zeit. Wer weiterhin so arbeitet, riskiert die Informationssicherheit seiner Umgebung.“
Wer alle seine Systeme einmal im Monat wartet und neustartet, bewegt sich in meiner Wahrnehmung aktuell im Mittelfeld dessen, was man im Feld findet. Doch auch hierauf darf sich niemand ausruhen. Existiert zu einem CVE ein Exploit und ein Patch, erscheint es fahrlässig, bis zu einem Monat mit dessen Installation zu warten.
Leider fehlt etlichen Unternehmen bzw. Organisationen noch immer die Fähigkeit schnell festzustellen, ob ihre IT-Dienste korrekt ausgeführt werden. Patch-Management-Zyklen sehen hier meist vor, dass zuerst einige Systeme aktualisiert werden, dann wartet man 1-2 Wochen, ob jemand meckert und dann aktualisiert man die restlichen Systeme. Das ist nicht mehr zeitgemäß.
Aus der eingangs beschriebenen Bedrohungslage folgend muss das neue Ziel lauten, jedes individuelle System an jedem Tag aktualisieren und neustarten zu können. Die Funktion von IT-Diensten ist durch automatisierte Mechanismen wie z.B. Monitoring oder automatisierte Tests zu verifizieren, um schnell mit der nächsten Stage fortfahren zu können. Wer dieses Ziel noch nicht erreicht hat, sollte sich schnellstens auf den Weg machen. Selbst wenn die 100% unerreichbar scheinen, ist jedes System, das man schnell absichern kann, ein deutlich geringeres Risiko für die eigene Informationssicherheit.
Wo Sicherheitsaktualisierungen nicht zeitnah eingespielt werden können, lässt sich das Risiko durch Verteidigung in der Tiefe minimieren. Kommunikationsverbindungen von und zu betrachteten Systemen sind zu überwachen und ggf. zu limitieren. Doch auch diese Maßnahmen müssen schnell verfügbar und umsetzbar sein. Wer erst zwei Wochen diskutieren muss, ob man den Zugriff auf einen Dienst einschränken könne, müsse, sollte, handelt nicht angemessen.
Zusammenfassend sehe ich unklare Verantwortlichkeiten, langwierige Abstimmungsprozesse und manuelle Tätigkeiten als Gift und Risiko für die Informationssicherheit. Klare Strukturen, geklärte Verantwortlichkeiten und Automation sind kein nice-to-have, sondern ein MUSS.
Wie geht ihr damit um?
Nun möchte ich von euch wissen: „Patcht ihr schon oder prozessiert ihr noch?“
Ich bin sehr daran interessiert zu erfahren, wie es in den Umgebungen meiner Lesenden und derer Bekannten zugeht. Daher freue ich mich sehr, wenn ihr (gern anonym) euer Patch-Management-Konzept, die Branche eures Unternehmens und die ungefähre Größe eurer Umgebung mit der Gemeinschaft bzw. mir teilt.
- Ihr habt euer Patch-Management im eigenen (Firmen-)Blog beschrieben? Teilt bitte den Link in den Kommentaren.
- Sendet mir gerne eine E-Mail an patchmanagement@my-it-brain.de.
- Beschreibt euer Patch-Management in den Kommentaren unter diesem Beitrag.
Evtl. werde ich eure Beispiele anonymisiert unter ausschließlicher Nennung der Branche (falls bekannt) in Vorträgen, Diskussion und weiteren Arbeiten zu diesem Thema verwenden. Bitte schreibt ausdrücklich dazu, wenn ihr dies nicht wünscht.
Ich freue mich auf eure Beiträge, Zusendungen und wenn ihr diesen Artikel in euren Netzwerken teilt.
